 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeetBench-XL: Calibrated Multi-Dimensional Evaluation and Learned Dual-Policy Agents for Real-Time Meetings
Feb 03, 2026Enterprise meeting environments require AI assistants that handle diverse operational tasks, from rapid fact checking during live discussions to cross meeting analysis for strategic planning, under strict latency, cost, and privacy constraints. Existing meeting benchmarks mainly focus on simplified question answering and fail to reflect real world enterprise workflows, where queries arise organically from multi stakeholder collaboration, span long temporal contexts, and require tool augmented reasoning. We address this gap through a grounded dataset and a learned agent framework. First, we introduce MeetAll, a bilingual and multimodal corpus derived from 231 enterprise meetings totaling 140 hours. Questions are injected using an enterprise informed protocol validated by domain expert review and human discriminability studies. Unlike purely synthetic benchmarks, this protocol is grounded in four enterprise critical dimensions: cognitive load, temporal context span, domain expertise, and actionable task execution, calibrated through interviews with stakeholders across finance, healthcare, and technology sectors. Second, we propose MeetBench XL, a multi dimensional evaluation protocol aligned with human judgment that measures factual fidelity, intent alignment, response efficiency, structural clarity, and completeness. Third, we present MeetMaster XL, a learned dual policy agent that jointly optimizes query routing between fast and slow reasoning paths and tool invocation, including retrieval, cross meeting aggregation, and web search. A lightweight classifier enables accurate routing with minimal overhead, achieving a superior quality latency tradeoff over single model baselines. Experiments against commercial systems show consistent gains, supported by ablations, robustness tests, and a real world deployment case study.Resources: https://github.com/huyuelin/MeetBench.
Entropy-Gated Selective Policy Optimization:Token-Level Gradient Allocation for Hybrid Training of Large Language Models
Feb 03, 2026Hybrid training methods for large language models combine supervised fine tuning (SFT) on expert demonstrations with reinforcement learning (RL) on model rollouts, typically at the sample level. We propose Entropy Gated Selective Policy Optimization (EGSPO), a three stage framework that extends sample level mixing with token level gradient modulation. Stage 1, SFT expert learning, establishes a reliable warm up policy using expert demonstrations with a pure SFT loss. Stage 2, RL rollout generation, samples trajectories from the current policy and computes per token predictive entropy. Stage 3, the EGSPO mechanism, applies entropy gated gradient allocation: a predictive entropy module routes high entropy tokens to full PPO updates to encourage exploration, and low entropy tokens to attenuated PPO updates to reduce variance and preserve knowledge. Critically, both branches incorporate the advantage function A_t, ensuring that incorrect trajectories receive consistent negative learning signals and preventing reinforcement of confident errors. EGSPO achieves consistent improvements on mathematical reasoning benchmarks, with gains of 3.8 percent on AIME and 2.9 percent on MATH over the CHORD phi baseline, while incurring only 3.4 percent additional computational overhead.
SurfSplat: Conquering Feedforward 2D Gaussian Splatting with Surface Continuity Priors
Feb 03, 2026Reconstructing 3D scenes from sparse images remains a challenging task due to the difficulty of recovering accurate geometry and texture without optimization. Recent approaches leverage generalizable models to generate 3D scenes using 3D Gaussian Splatting (3DGS) primitive. However, they often fail to produce continuous surfaces and instead yield discrete, color-biased point clouds that appear plausible at normal resolution but reveal severe artifacts under close-up views. To address this issue, we present SurfSplat, a feedforward framework based on 2D Gaussian Splatting (2DGS) primitive, which provides stronger anisotropy and higher geometric precision. By incorporating a surface continuity prior and a forced alpha blending strategy, SurfSplat reconstructs coherent geometry together with faithful textures. Furthermore, we introduce High-Resolution Rendering Consistency (HRRC), a new evaluation metric designed to evaluate high-resolution reconstruction quality. Extensive experiments on RealEstate10K, DL3DV, and ScanNet demonstrate that SurfSplat consistently outperforms prior methods on both standard metrics and HRRC, establishing a robust solution for high-fidelity 3D reconstruction from sparse inputs. Project page: https://hebing-sjtu.github.io/SurfSplat-website/
Lightweight High-Fidelity Low-Bitrate Talking Face Compression for 3D Video Conference
Jan 29, 2026The demand for immersive and interactive communication has driven advancements in 3D video conferencing, yet achieving high-fidelity 3D talking face representation at low bitrates remains a challenge. Traditional 2D video compression techniques fail to preserve fine-grained geometric and appearance details, while implicit neural rendering methods like NeRF suffer from prohibitive computational costs. To address these challenges, we propose a lightweight, high-fidelity, low-bitrate 3D talking face compression framework that integrates FLAME-based parametric modeling with 3DGS neural rendering. Our approach transmits only essential facial metadata in real time, enabling efficient reconstruction with a Gaussian-based head model. Additionally, we introduce a compact representation and compression scheme, including Gaussian attribute compression and MLP optimization, to enhance transmission efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance, delivering high-quality facial rendering at extremely low bitrates, making it well-suited for real-time 3D video conferencing applications.
Joint Source-Channel-Generation Coding: From Distortion-oriented Reconstruction to Semantic-consistent Generation
Jan 19, 2026Conventional communication systems, including both separation-based coding and AI-driven joint source-channel coding (JSCC), are largely guided by Shannon's rate-distortion theory. However, relying on generic distortion metrics fails to capture complex human visual perception, often resulting in blurred or unrealistic reconstructions. In this paper, we propose Joint Source-Channel-Generation Coding (JSCGC), a novel paradigm that shifts the focus from deterministic reconstruction to probabilistic generation. JSCGC leverages a generative model at the receiver as a generator rather than a conventional decoder to parameterize the data distribution, enabling direct maximization of mutual information under channel constraints while controlling stochastic sampling to produce outputs residing on the authentic data manifold with high fidelity. We further derive a theoretical lower bound on the maximum semantic inconsistency with given transmitted mutual information, elucidating the fundamental limits of communication in controlling the generative process. Extensive experiments on image transmission demonstrate that JSCGC substantially improves perceptual quality and semantic fidelity, significantly outperforming conventional distortion-oriented JSCC methods.
MultiEgo: A Multi-View Egocentric Video Dataset for 4D Scene Reconstruction
Dec 12, 2025Multi-view egocentric dynamic scene reconstruction holds significant research value for applications in holographic documentation of social interactions. However, existing reconstruction datasets focus on static multi-view or single-egocentric view setups, lacking multi-view egocentric datasets for dynamic scene reconstruction. Therefore, we present MultiEgo, the first multi-view egocentric dataset for 4D dynamic scene reconstruction. The dataset comprises five canonical social interaction scenes: meetings, performances, and a presentation. Each scene provides five authentic egocentric videos captured by participants wearing AR glasses. We design a hardware-based data acquisition system and processing pipeline, achieving sub-millisecond temporal synchronization across views, coupled with accurate pose annotations. Experiment validation demonstrates the practical utility and effectiveness of our dataset for free-viewpoint video (FVV) applications, establishing MultiEgo as a foundational resource for advancing multi-view egocentric dynamic scene reconstruction research.
Spatial Computing Communications for Multi-User Virtual Reality in Distributed Mobile Edge Computing Network
Oct 16, 2025Immersive virtual reality (VR) applications impose stringent requirements on latency, energy efficiency, and computational resources, particularly in multi-user interactive scenarios. To address these challenges, we introduce the concept of spatial computing communications (SCC), a framework designed to meet the latency and energy demands of multi-user VR over distributed mobile edge computing (MEC) networks. SCC jointly represents the physical space, defined by users and base stations, and the virtual space, representing shared immersive environments, using a probabilistic model of user dynamics and resource requirements. The resource deployment task is then formulated as a multi-objective combinatorial optimization (MOCO) problem that simultaneously minimizes system latency and energy consumption across distributed MEC resources. To solve this problem, we propose MO-CMPO, a multi-objective consistency model with policy optimization that integrates supervised learning and reinforcement learning (RL) fine-tuning guided by preference weights. Leveraging a sparse graph neural network (GNN), MO-CMPO efficiently generates Pareto-optimal solutions. Simulations with real-world New Radio base station datasets demonstrate that MO-CMPO achieves superior hypervolume performance and significantly lower inference latency than baseline methods. Furthermore, the analysis reveals practical deployment patterns: latency-oriented solutions favor local MEC execution to reduce transmission delay, while energy-oriented solutions minimize redundant placements to save energy.
AlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views
Oct 09, 2025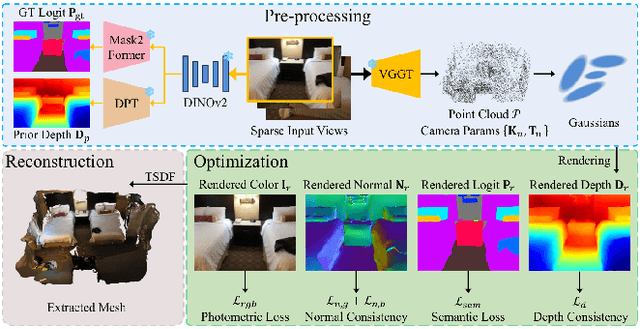
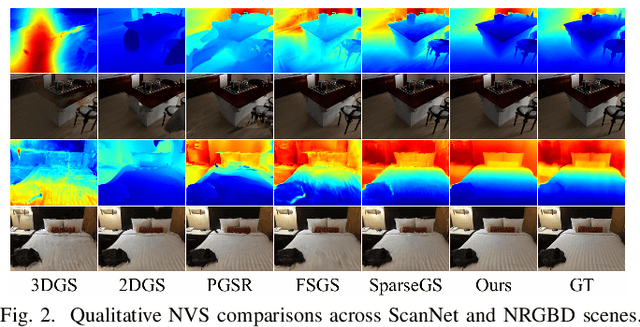
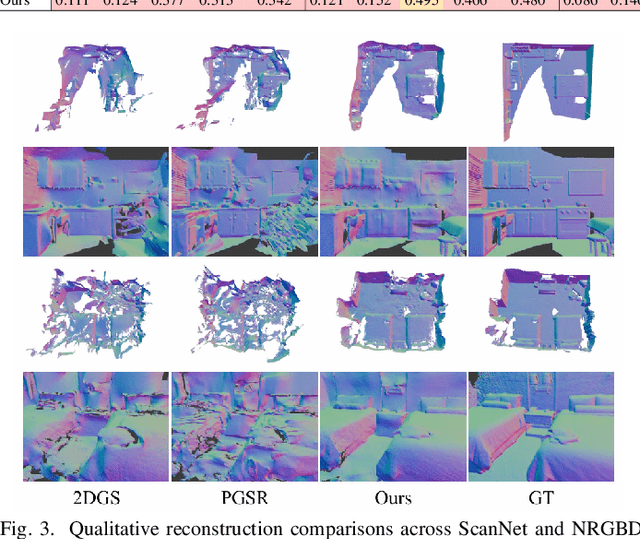
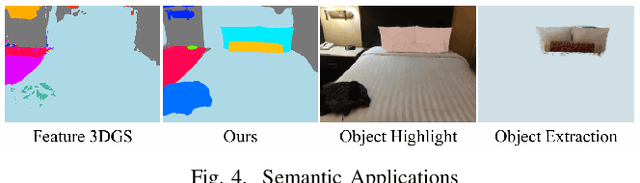
The demand for semantically rich 3D models of indoor scenes is rapidly growing, driven by applications in augmented reality, virtual reality, and robotics. However, creating them from sparse views remains a challenge due to geometric ambiguity. Existing methods often treat semantics as a passive feature painted on an already-formed, and potentially flawed, geometry. We posit that for robust sparse-view reconstruction, semantic understanding instead be an active, guiding force. This paper introduces AlignGS, a novel framework that actualizes this vision by pioneering a synergistic, end-to-end optimization of geometry and semantics. Our method distills rich priors from 2D foundation models and uses them to directly regularize the 3D representation through a set of novel semantic-to-geometry guidance mechanisms, including depth consistency and multi-faceted normal regularization. Extensive evaluations on standard benchmarks demonstrate that our approach achieves state-of-the-art results in novel view synthesis and produces reconstructions with superior geometric accuracy. The results validate that leveraging semantic priors as a geometric regularizer leads to more coherent and complete 3D models from limited input views. Our code is avaliable at https://github.com/MediaX-SJTU/AlignGS .
PrismGS: Physically-Grounded Anti-Aliasing for High-Fidelity Large-Scale 3D Gaussian Splatting
Oct 09, 20253D Gaussian Splatting (3DGS) has recently enabled real-time photorealistic rendering in compact scenes, but scaling to large urban environments introduces severe aliasing artifacts and optimization instability, especially under high-resolution (e.g., 4K) rendering. These artifacts, manifesting as flickering textures and jagged edges, arise from the mismatch between Gaussian primitives and the multi-scale nature of urban geometry. While existing ``divide-and-conquer'' pipelines address scalability, they fail to resolve this fidelity gap. In this paper, we propose PrismGS, a physically-grounded regularization framework that improves the intrinsic rendering behavior of 3D Gaussians. PrismGS integrates two synergistic regularizers. The first is pyramidal multi-scale supervision, which enforces consistency by supervising the rendering against a pre-filtered image pyramid. This compels the model to learn an inherently anti-aliased representation that remains coherent across different viewing scales, directly mitigating flickering textures. This is complemented by an explicit size regularization that imposes a physically-grounded lower bound on the dimensions of the 3D Gaussians. This prevents the formation of degenerate, view-dependent primitives, leading to more stable and plausible geometric surfaces and reducing jagged edges. Our method is plug-and-play and compatible with existing pipelines. Extensive experiments on MatrixCity, Mill-19, and UrbanScene3D demonstrate that PrismGS achieves state-of-the-art performance, yielding significant PSNR gains around 1.5 dB against CityGaussian, while maintaining its superior quality and robustness under demanding 4K rendering.
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing
Aug 12, 2025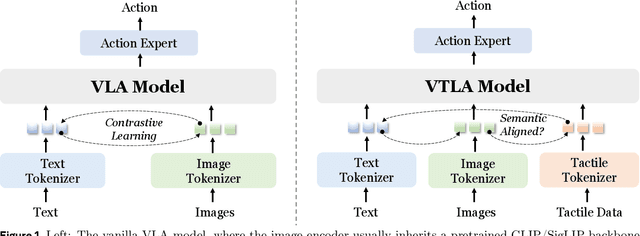

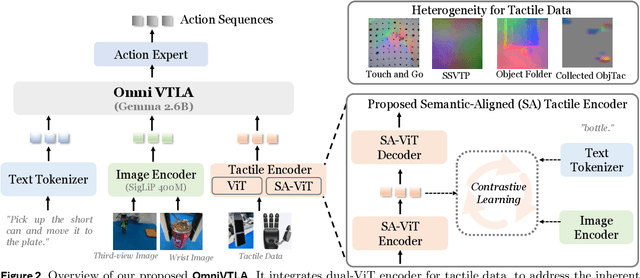

Recent vision-language-action (VLA) models build upon vision-language foundations, and have achieved promising results and exhibit the possibility of task generalization in robot manipulation. However, due to the heterogeneity of tactile sensors and the difficulty of acquiring tactile data, current VLA models significantly overlook the importance of tactile perception and fail in contact-rich tasks. To address this issue, this paper proposes OmniVTLA, a novel architecture involving tactile sensing. Specifically, our contributions are threefold. First, our OmniVTLA features a dual-path tactile encoder framework. This framework enhances tactile perception across diverse vision-based and force-based tactile sensors by using a pretrained vision transformer (ViT) and a semantically-aligned tactile ViT (SA-ViT). Second, we introduce ObjTac, a comprehensive force-based tactile dataset capturing textual, visual, and tactile information for 56 objects across 10 categories. With 135K tri-modal samples, ObjTac supplements existing visuo-tactile datasets. Third, leveraging this dataset, we train a semantically-aligned tactile encoder to learn a unified tactile representation, serving as a better initialization for OmniVTLA. Real-world experiments demonstrate substantial improvements over state-of-the-art VLA baselines, achieving 96.9% success rates with grippers, (21.9% higher over baseline) and 100% success rates with dexterous hands (6.2% higher over baseline) in pick-and-place tasks. Besides, OmniVTLA significantly reduces task completion time and generates smoother trajectories through tactile sensing compared to existing VLA.